Training Sparse Autoencoders
Methods development for training SAEs is rapidly evolving, so these docs may change frequently. For all available training options, see the LanguageModelSAERunnerConfig and the architecture-specific configuration classes it uses (e.g., StandardTrainingSAEConfig, GatedTrainingSAEConfig, JumpReLUTrainingSAEConfig, and TopKTrainingSAEConfig).
However, we are attempting to maintain this tutorial
![]() .
.
We encourage readers to join the Open Source Mechanistic Interpretability Slack for support!
Basic training setup
Training a SAE is done using the SAETrainingRunner class. This class is configured using a LanguageModelSAERunnerConfig. The LanguageModelSAERunnerConfig holds parameters for the overall training run (like model, dataset, and learning rate), and it contains an sae field. This sae field should be an instance of an architecture-specific SAE configuration dataclass (e.g., StandardTrainingSAEConfig for standard SAEs, TopKTrainingSAEConfig for TopK SAEs, etc.), which holds parameters specific to the SAE's structure and sparsity mechanisms.
When using the command-line interface (CLI), you typically specify an --architecture argument (e.g., "standard", "gated", "jumprelu", "topk"), and the runner constructs the appropriate nested SAE configuration. When instantiating LanguageModelSAERunnerConfig programmatically, you should directly provide the configured SAE object to the sae field.
Some of the core config options available in LanguageModelSAERunnerConfig are:
model_name: The base model name to train a SAE on (e.g.,"gpt2-small","tiny-stories-1L-21M"). This must correspond to a model from TransformerLens or a Hugging FaceAutoModelForCausalLMifmodel_class_nameis set accordingly.hook_name: This is a TransformerLens hook in the model where our SAE will be trained from (e.g.,"blocks.0.hook_mlp_out"). More info on hooks can be found here.hook_layer: This is an int which corresponds to the layer specified inhook_name. This must match! e.g. ifhook_nameis"blocks.3.hook_mlp_out", thenhook_layermust be3.dataset_path: The path to a dataset on Huggingface for training (e.g.,"apollo-research/roneneldan-TinyStories-tokenizer-gpt2").training_tokens: The total number of tokens from the dataset to use for training the SAE.train_batch_size_tokens: The batch size used for training the SAE, measured in tokens. Adjust this to keep the GPU saturated.model_from_pretrained_kwargs: A dictionary of keyword arguments to pass toHookedTransformer.from_pretrainedwhen loading the model. It's often best to set"center_writing_weights": False.lr: The learning rate for the optimizer.context_size: The sequence length of prompts fed to the model to generate activations.
Core options typically configured within the architecture-specific sae object (e.g., cfg.sae = StandardTrainingSAEConfig(...)):
d_in: The input dimensionality of the SAE. This must match the size of the activations athook_name.expansion_factor: The SAE's hidden layer will have dimensionalityexpansion_factor * d_in.activation_fn: The activation function for the SAE's hidden layer (e.g.,"relu","gelu"). For TopK SAEs, this is effectively fixed by the TopK mechanism.- Sparsity control parameters: These vary by architecture:
- For Standard SAEs:
l1_coefficient(controls L1 penalty),lp_norm(e.g., 1.0 for L1, 0.7 for L0.7),l1_warm_up_steps. - For Gated SAEs:
l1_coefficient(controls L1-like penalty on gate activations),l1_warm_up_steps. - For JumpReLU SAEs:
l0_coefficient(controls L0-like penalty),l0_warm_up_steps,jumprelu_init_threshold,jumprelu_bandwidth. - For TopK SAEs:
k(the number of features to keep active). Sparsity is enforced structurally. normalize_sae_decoder: Whether to normalize the SAE decoder weights.decoder_heuristic_init: Whether to use heuristic initialization for the decoder.init_encoder_as_decoder_transpose: Whether to initialize the encoder as the transpose of the decoder.normalize_activations: Strategy for normalizing activations before they enter the SAE (e.g.,"expected_average_only_in").
A sample training run from the tutorial is shown below. Note how SAE-specific parameters are nested within the sae field:
from sae_lens import LanguageModelSAERunnerConfig, SAETrainingRunner
from sae_lens.saes import StandardTrainingSAEConfig # Import the specific SAE config
# Define total training steps and batch size
total_training_steps = 30_000
batch_size = 4096
total_training_tokens = total_training_steps * batch_size
# Learning rate and L1 warmup schedules
lr_warm_up_steps = 0
lr_decay_steps = total_training_steps // 5 # 20% of training
l1_warm_up_steps = total_training_steps // 20 # 5% of training
# Assume 'device' is defined (e.g., "cuda" or "cpu")
device = "cuda" if torch.cuda.is_available() else "cpu" # Example device definition
import torch # Required for the device check
cfg = LanguageModelSAERunnerConfig(
# Data Generating Function (Model + Training Distribution)
model_name="tiny-stories-1L-21M",
hook_name="blocks.0.hook_mlp_out",
hook_layer=0,
dataset_path="apollo-research/roneneldan-TinyStories-tokenizer-gpt2",
is_dataset_tokenized=True,
streaming=True,
# SAE Parameters are in the nested 'sae' config
sae=StandardTrainingSAEConfig(
d_in=1024, # Matches hook_mlp_out for tiny-stories-1L-21M
expansion_factor=16,
b_dec_init_method="zeros",
apply_b_dec_to_input=False,
normalize_sae_decoder=False,
scale_sparsity_penalty_by_decoder_norm=True,
decoder_heuristic_init=True,
init_encoder_as_decoder_transpose=True,
normalize_activations="expected_average_only_in",
mse_loss_normalization=None,
l1_coefficient=5,
lp_norm=1.0,
l1_warm_up_steps=l1_warm_up_steps,
# activation_fn: "relu" by default in StandardTrainingSAEConfig
),
# Training Parameters
lr=5e-5,
adam_beta1=0.9,
adam_beta2=0.999,
lr_scheduler_name="constant",
lr_warm_up_steps=lr_warm_up_steps,
lr_decay_steps=lr_decay_steps,
train_batch_size_tokens=batch_size,
context_size=256,
# Activation Store Parameters
n_batches_in_buffer=64,
training_tokens=total_training_tokens,
store_batch_size_prompts=16,
# Resampling protocol args
use_ghost_grads=False, # Ghost grads are part of TrainingSAEConfig, default False
feature_sampling_window=1000,
dead_feature_window=1000,
dead_feature_threshold=1e-4,
# WANDB
logger_cfg=dict( # Assuming LoggingConfig is handled via a dict or a LoggingConfig instance
log_to_wandb=True,
wandb_project="sae_lens_tutorial",
wandb_log_frequency=30,
eval_every_n_wandb_logs=20,
),
# Misc
device=device,
seed=42,
n_checkpoints=0,
checkpoint_path="checkpoints",
dtype="float32"
)
# sparse_autoencoder = SAETrainingRunner(cfg).run() # Commented out to prevent execution in docs
As you can see, the training setup provides a large number of options to explore. The full list of options can be found by inspecting the LanguageModelSAERunnerConfig class and the specific SAE configuration class you intend to use (e.g., StandardTrainingSAEConfig, TopKTrainingSAEConfig, etc.).
Training Topk SAEs
By default, SAELens will train SAEs using a L1 loss term with ReLU activation. A popular alternative architecture is the TopK architecture, which fixes the L0 of the SAE using a TopK activation function. To train a TopK SAE programmatically, you provide a TopKTrainingSAEConfig instance to the sae field. The primary parameter for TopK SAEs is k, the number of features to keep active. If not set, k defaults to 100 in TopKTrainingSAEConfig. The TopK architecture does not use an l1_coefficient or lp_norm for sparsity, as sparsity is structurally enforced.
from sae_lens import LanguageModelSAERunnerConfig, SAETrainingRunner
from sae_lens.saes import TopKTrainingSAEConfig # Import TopK config
# cfg = LanguageModelSAERunnerConfig( # Full config would be defined here
# # ... other LanguageModelSAERunnerConfig parameters ...
# sae=TopKTrainingSAEConfig(
# k=100, # Set the number of active features
# d_in=1024, # Example, must match your hook point
# expansion_factor=16, # Example
# # ... other common SAE parameters from SAEConfig if needed ...
# ),
# # ...
# )
# sparse_autoencoder = SAETrainingRunner(cfg).run() # Commented out
Training JumpReLU SAEs
JumpReLU SAEs are a state-of-the-art SAE architecture. To train one, provide a JumpReLUTrainingSAEConfig to the sae field. JumpReLU SAEs use a sparsity penalty controlled by the l0_coefficient parameter. The JumpReLUTrainingSAEConfig also has parameters jumprelu_bandwidth and jumprelu_init_threshold which affect the learning of the thresholds.
from sae_lens import LanguageModelSAERunnerConfig, SAETrainingRunner
from sae_lens.saes import JumpReLUTrainingSAEConfig # Import JumpReLU config
# cfg = LanguageModelSAERunnerConfig( # Full config would be defined here
# # ... other LanguageModelSAERunnerConfig parameters ...
# sae=JumpReLUTrainingSAEConfig(
# l0_coefficient=5.0, # Sparsity penalty coefficient
# jumprelu_bandwidth=0.001,
# jumprelu_init_threshold=0.001,
# d_in=1024, # Example, must match your hook point
# expansion_factor=16, # Example
# # ... other common SAE parameters from SAEConfig ...
# ),
# # ...
# )
# sparse_autoencoder = SAETrainingRunner(cfg).run() # Commented out
Training Gated SAEs
Gated SAEs are another architecture option. To train a Gated SAE, provide a GatedTrainingSAEConfig to the sae field. Gated SAEs use the l1_coefficient parameter to control the sparsity of the SAE, similar to standard SAEs.
from sae_lens import LanguageModelSAERunnerConfig, SAETrainingRunner
from sae_lens.saes import GatedTrainingSAEConfig # Import Gated config
# cfg = LanguageModelSAERunnerConfig( # Full config would be defined here
# # ... other LanguageModelSAERunnerConfig parameters ...
# sae=GatedTrainingSAEConfig(
# l1_coefficient=5.0, # Sparsity penalty coefficient
# d_in=1024, # Example, must match your hook point
# expansion_factor=16, # Example
# # ... other common SAE parameters from SAEConfig ...
# ),
# # ...
# )
# sparse_autoencoder = SAETrainingRunner(cfg).run() # Commented out
CLI Runner
The SAE training runner can also be run from the command line via the sae_lens.sae_training_runner module. This can be useful for quickly testing different hyperparameters or running training on a remote server. The command line interface is shown below. All options to the CLI are the same as the LanguageModelSAERunnerConfig with a -- prefix. E.g., --model_name is the same as model_name in the config.
Logging to Weights and Biases
For any real training run, you should be logging to Weights and Biases (WandB). This will allow you to track your training progress and compare different runs. To enable WandB, set log_to_wandb=True. The wandb_project parameter in the config controls the project name in WandB. You can also control the logging frequency with wandb_log_frequency and eval_every_n_wandb_logs.
A number of helpful metrics are logged to WandB, including the sparsity of the SAE, the mean squared error (MSE) of the SAE, dead features, and explained variance. These metrics can be used to monitor the training progress and adjust the training parameters. Below is a screenshot from one training run.
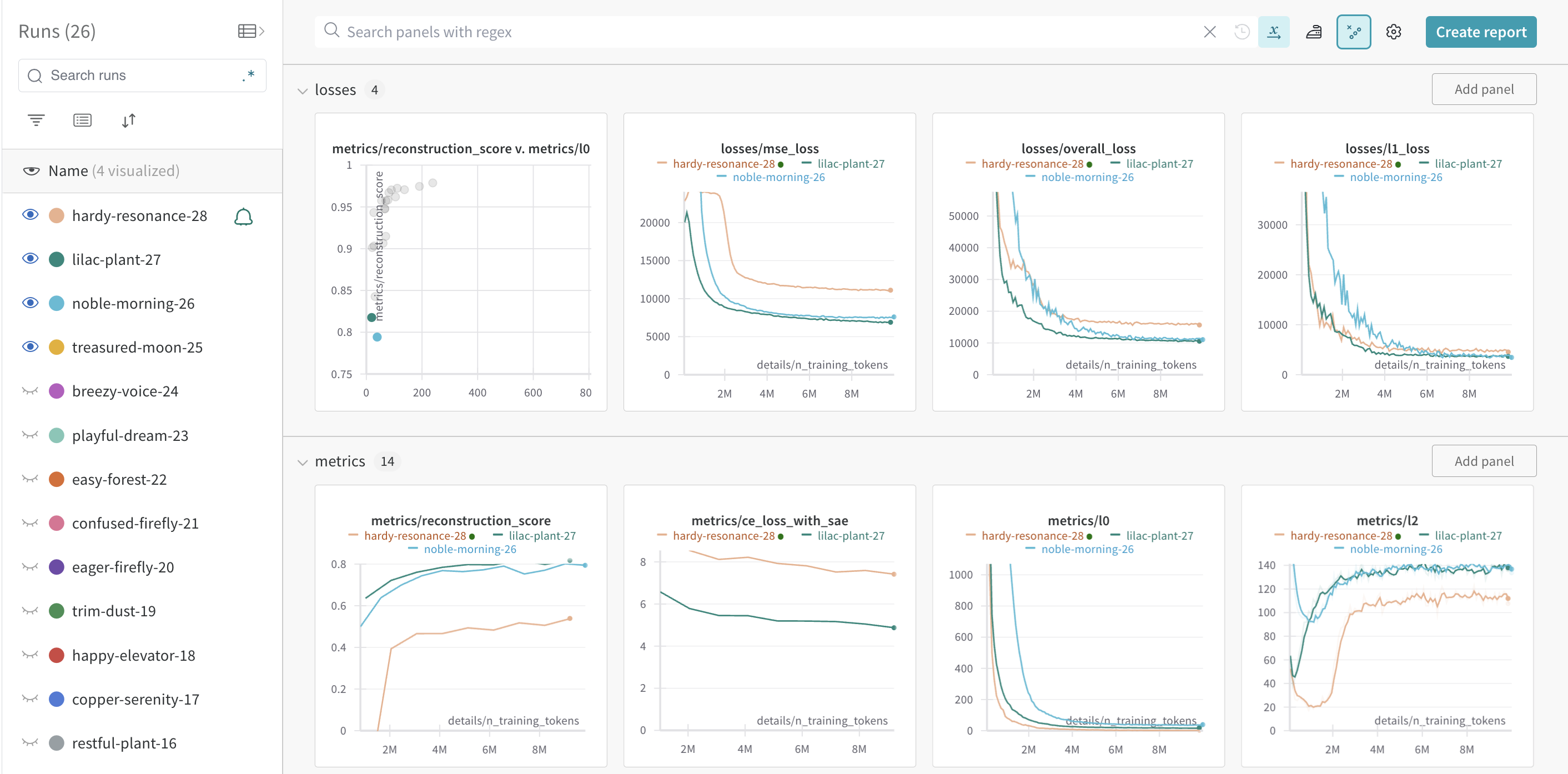
Best practices for real SAEs
It may sound daunting to train a real SAE but nothing could be further from the truth! You can typically train a decent SAE for a real LLM on a single A100 GPU in a matter of hours.
SAE Training best practices are still rapidly evolving, so the default settings in SAELens may not be optimal for real SAEs. Fortunately, it's easy to see what any SAE trained using SAELens used for its training configuration and just copy its values as a starting point! If there's a SAE on Huggingface trained using SAELens, you can see all the training settings used by looking at the cfg.json file in the SAE's repo. For instance, here's the cfg.json for a Gemma 2B standard SAE trained by Joseph Bloom. You can also get the config in SAELens as the second return value from SAE.from_pretrained(). For instance, the same config mentioned above can be accessed as cfg_dict = SAE.from_pretrained("jbloom/Gemma-2b-Residual-Stream-SAEs", "gemma_2b_blocks.12.hook_resid_post_16384")[1]. You can browse all SAEs uploaded to Huggingface via SAELens to get some inspiration with the SAELens library tag.
Some general performance tips:
- If your GPU supports it (most modern nvidia-GPUs do), setting
autocast=Trueandautocast_lm=Truein the config will dramatically speed up training. - We find that often SAEs struggle to train well with
dtype="bfloat16". We aren't sure why this is, but make sure to compare the SAE quality if you change the dtype. - You can try turning on
compile_sae=Trueandcompile_llm=Truein the config to see if it makes training faster. Your mileage may vary though, compilation can be finicky.
JumpReLU SAEs
JumpReLU SAEs are a state-of-the-art SAE architecture from DeepMind which at present gives the best known sparsity vs reconstruction error trade-off, and is the architecture used for Gemma Scope SAEs. However, JumpReLU SAEs are slightly trickier to train than standard SAEs due to how the threshold is learned. We recommend the following tips for training JumpReLU SAEs:
- Make sure to train on enough tokens. We've found that at least 2B tokens and ideally 4B tokens is needed for good performance with the default
jumprelu_bandwidthsetting. This may vary depending on the model and SAE size though, so make sure to monitor the training logs to ensure convergence. - Set
normalize_activations="expected_average_only_in"in the config. This helps with convergence and is generally a good idea for all SAEs.
You can find a sample config for a Gemma-2-2B JumpReLU SAE trained via SAELens here: cfg.json
Checkpoints
Checkpoints allow you to save a snapshot of the SAE and sparsitity statistics during training. To enable checkpointing, set n_checkpoints to a value larger than 0. If WandB logging is enabled, checkpoints will be uploaded as WandB artifacts. To save checkpoints locally, the checkpoint_path parameter can be set to a local directory.
Optimizers and Schedulers
The SAE training runner uses the Adam optimizer with a constant learning rate by default. The optimizer betas can be controlled with the settings adam_beta1 and adam_beta2.
The learning rate scheduler can be controlled with the lr_scheduler_name parameter. The available schedulers are: constant (default), consineannealing, and cosineannealingwarmrestarts. All schedulers can be used with linear warmup and linear decay, set via lr_warm_up_steps and lr_decay_steps.
To avoid dead features, it's often helpful to slowly increase the L1 penalty. This can be done by setting l1_warm_up_steps to a value larger than 0. This will linearly increase the L1 penalty over the first l1_warm_up_steps training steps.
Training on Huggingface Models
While TransformerLens is the recommended way to use SAELens, it is also possible to use any Huggingface AutoModelForCausalLM as the model. This is useful if you want to use a model that is not supported by TransformerLens, or if you cannot use TransformerLens due to memory or performance reasons. To use a Huggingface AutoModelForCausalLM, you can specify model_class_name = 'AutoModelForCausalLM' in the SAE config. Your hook points will then need to correspond to the named parameters of the Huggingface model rather than the typical TransformerLens hook points. For instance, if you were using GPT2 from Huggingface, you would use hook_name = 'transformer.h.1' rather than hook_name = 'blocks.1.hook_resid_post'. Otherwise everything should work the same as with TransformerLens models.
Datasets, streaming, and context size
SAELens works with datasets hosted on Huggingface. However, these datsets are often very large and take a long time and a lot of disk space to download. To speed this up, you can set streaming=True in the config. This will stream the dataset from Huggingface during training, which will allow training to start immediately and save disk space.
The context_size parameter controls the length of the prompts fed to the model. Larger context sizes will result in better SAE performance, but will also slow down training. Each training batch will be tokens of size train_batch_size_tokens x context_size.
It's also possible to use pre-tokenized datasets to speed up training, since tokenization can be a bottleneck. To use a pre-tokenized dataset on Huggingface, update the dataset_path parameter and set is_dataset_tokenized=True in the config.
Pretokenizing datasets
We also provider a runner, PretokenizeRunner, which can be used to pre-tokenize a dataset and upload it to Huggingface. See PretokenizeRunnerConfig for all available options. We also provide a pretokenizing datasets tutorial with more details.
A sample run from the tutorial for GPT2 and the NeelNanda/c4-10k dataset is shown below.
from sae_lens import PretokenizeRunner, PretokenizeRunnerConfig
cfg = PretokenizeRunnerConfig(
tokenizer_name="gpt2",
dataset_path="NeelNanda/c4-10k", # this is just a tiny test dataset
shuffle=True,
num_proc=4, # increase this number depending on how many CPUs you have
# tweak these settings depending on the model
context_size=128,
begin_batch_token="bos",
begin_sequence_token=None,
sequence_separator_token="eos",
# uncomment to upload to huggingface
# hf_repo_id="your-username/c4-10k-tokenized-gpt2"
# uncomment to save the dataset locally
# save_path="./c4-10k-tokenized-gpt2"
)
dataset = PretokenizeRunner(cfg).run()
List of Pretokenized datasets
Below is a list of pre-tokenized datasets that can be used with SAELens. If you have a dataset you would like to add to this list, please open a PR!
| Huggingface ID | Tokenizer | Source Dataset | context size | Created with SAELens |
|---|---|---|---|---|
| chanind/openwebtext-gemma | gemma | Skylion007/openwebtext | 8192 | Yes |
| chanind/openwebtext-llama3 | llama3 | Skylion007/openwebtext | 8192 | Yes |
| apollo-research/Skylion007-openwebtext-tokenizer-EleutherAI-gpt-neox-20b | EleutherAI/gpt-neox-20b | Skylion007/openwebtext | 2048 | No |
| apollo-research/monology-pile-uncopyrighted-tokenizer-EleutherAI-gpt-neox-20b | EleutherAI/gpt-neox-20b | monology/pile-uncopyrighted | 2048 | No |
| apollo-research/monology-pile-uncopyrighted-tokenizer-gpt2 | gpt2 | monology/pile-uncopyrighted | 1024 | No |
| apollo-research/Skylion007-openwebtext-tokenizer-gpt2 | gpt2 | Skylion007/openwebtext | 1024 | No |
| GulkoA/TinyStories-tokenized-Llama-3.2 | llama3.2 | roneneldan/TinyStories | 128 | Yes |
Caching activations
The next step in improving performance beyond pre-tokenizing datasets is to cache model activations. This allows you to pre-calculate all the training activations for your SAE in advance so the model does not need to be run during training to generate activations. This allows rapid training of SAEs and is especially helpful for experimenting with training hyperparameters. However, pre-calculating activations can take a very large amount of disk space, so it may not always be possible.
SAELens provides a CacheActivationsRunner class to help with pre-calculating activations. See CacheActivationsRunnerConfig for all available options. This runner intentionally shares a lot of options with LanguageModelSAERunnerConfig. These options should be set identically when using the cached activations in training. The CacheActivationsRunner can be used as below:
from sae_lens import CacheActivationsRunner, CacheActivationsRunnerConfig
cfg = CacheActivationsRunnerConfig(
model_name="tiny-stories-1L-21M",
hook_name="blocks.0.hook_mlp_out",
dataset_path="apollo-research/roneneldan-TinyStories-tokenizer-gpt2",
# ...
new_cached_activations_path="./tiny-stories-1L-21M-cache",
hf_repo_id="your-username/tiny-stories-1L-21M-cache", # To push to hub
)
CacheActivationsRunner(cfg).run()
To use the cached activations during training, set use_cached_activations=True and cached_activations_path to match the new_cached_activations_path above option in training configuration.
Uploading SAEs to Huggingface
Once you have a set of SAEs that you're happy with, your next step is to share them with the world! SAELens has a upload_saes_to_huggingface() function which makes this easy to do. We also provide a uploading saes to huggingface tutorial with more details.
You'll just need to pass a dictionary of SAEs to upload along with the huggingface repo id to upload to. The dictionary keys will become the folders in the repo where each SAE will be located. It's best practice to use the hook point that the SAE was trained on as the key to make it clear to users where in the model to apply the SAE. The values of this dictionary can be either an SAE object, or a path to a saved SAE object on disk from the sae.save_model() method.
A sample is shown below: